
一、Neo4j底层架构
1.Neo4j简介
Neo4j是一个高性能的,NOSQL图形数据库,它将结构化数据存储在网络上而不是表中。Neo4j也可以被看作是一个高性能的图引擎,该引擎具有成熟数据库的所有特性。程序员工作在一个面向对象的、灵活的网络结构下而不是严格、静态的表中——但是他们可以享受到具备完全的事务特性、企业级的数据库的所有好处。
Neo4j因其嵌入式、高性能、轻量级等优势,越来越受到关注。
2.存储结构
neo4j主要是由:Nodes(节点)和Relationships(关系)组成。并且节点和关系都是包含key/value形式的属性。所有的node通过Relationships所定义的关系相连起来,形成一个关系网络结构。
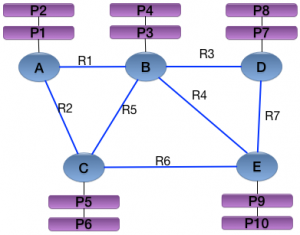
在这个例子中,A~E表示Node 的编号,R1~R7 表示 Relationship 编号,P1~P10 表示Property 的编号。
二、Neo4j索引
schema index和legacy index 都是基于lucene实现;
如果你正在使用Neo4j 2.0或者更高版本并且不需要支持2.0版本之前legacy index的代码,那么请只使用schema index同时避免legacy index;
如果你不得不使用Neo4j的早期版本,并且无法升级,无论如何你都只有一种索引可以选择(legacy index);
如果你需要全文检索的索引,不管是什么版本,都将使用legacy index。
1. schema index
创建索引方式
创建单一属性索引
CREATE INDEX ON : Person(firstname)删除单一属性索引
DROP INDEX ON :Person(firstname)创建复合索引
CREATE INDEX ON : Person(age, country)删除复合索引
DROP INDEX ON :Person(age, country)存储方式
schema index存储方式为复合索引(Compound Index),除了段信息文件,锁文件,以及删除的文件外,其他的一系列索引文件压缩一个后缀名为cfs的文件,即所有的索引文件会被存储成一个单例的Directory,
此方式有助于减少索引文件数量,减少同时打开的文件数量,从而获取更高的效率。比如说,查询频繁,而不经常更新的需求,就很适合这种索引格式。
2. legacy index
在Neo4j 2.0版本之前,Legacy index被称作indexes。这个索引是在graph外部通过Lucene实现,允许“节点”和“关系”以键值对的形式被检索。从Neo4j 提供的REST接口来看,被称作index的变量通常是指Legacy indexes;
Legacy index能够提供全文本检索的能力。这个功能并没有在schema index中被提供,这也是Neo4j 2.0* 版本保留legacy indexes的原因之一。
部分配置参数
三、Neo4j全文索引方式
1. call和yield的用法
首先看看这两个词的用方法。CALL语句用于调用数据库中的过程(Procedure),YIELD子句用于显示的选择返回结果集中的哪些部分并绑定到一个变量以供后续查询引用。简单说就是用call来调用函数,用yield来接收函数返回的结果。我们举个例子
call db.labels() yield label
return count(label) as num2. B-树和全文索引的区别
在Neo4j中,有两种不同的索引类型:B-树和全文索引
可以使用Cypher创建和删除B-树索引。用户通常不必知道索引就可以使用它,因为Cypher的查询计划器会决定在哪种情况下使用哪个索引。B-树索引擅长于对所有类型的值进行精确查找,以及范围扫描,完整扫描和前缀搜索。比如(=,>,start with,contains)等
全文索引与B-树索引不同,它们针对索引和搜索文本进行了优化。它们用于需要理解语言的查询,并且仅索引字符串数据。还必须通过过程明确查询它们。全文索引需要手动去创建它,查询的时候也是手动去调用。
在理解了索引的两种概念后,我们着手看看全文索引怎么创建。
3. 创建全文索引的核心API
创建全文索引
方法:
db.index.fulltext.createNodeIndex描述:为给定的标签和属性创建节点全文索引。可选的 'config' 映射参数可用于为索引提供设置。注意:特定于索引的设置目前是实验性的,可能无法在集群中或在备份期间正确复制。支持的设置是“分析器”,用于指定索引和查询时使用的分析器。使用该db.index.fulltext.listAvailableAnalyzers过程查看可用的选项。并且 'eventually_consistent' 可以设置为 'true' 以使该索引最终保持一致,以便在后台线程中应用来自提交事务的更新。
例子:
CALL db.index.fulltext.createNodeIndex("companyFullIndex",["CompanyEntry"],["name"], { analyzer: "cjk"}创建全文关系索引
方法:
db.index.fulltext.createRelationshipIndex描述:为给定的关系类型和属性创建关系全文索引。可选的 'config' 映射参数可用于为索引提供设置。注意:特定于索引的设置目前是实验性的,可能无法在集群中或在备份期间正确复制。支持的设置是“分析器”,用于指定索引和查询时使用的分析器。使用该db.index.fulltext.listAvailableAnalyzers过程查看可用的选项。并且 'eventually_consistent' 可以设置为 'true' 以使该索引最终保持一致,以便在后台线程中应用来自提交事务的更新。
列出可用的分析器
方法:
db.index.fulltext.listAvailableAnalyzers描述:列出可以配置全文索引的可用分析器。
使用全文节点索引
方法:
db.index.fulltext.queryNodes描述:查询给定的全文索引。返回匹配节点及其 Lucene 查询分数,按分数排序。
使用全文关系索引
db.index.fulltext.queryRelationships描述:查询给定的全文索引。返回匹配关系及其 Lucene 查询分数,按分数排序。
删除全文索引
db.index.fulltext.drop描述:删除指定的索引。
四、中文全文检索方式
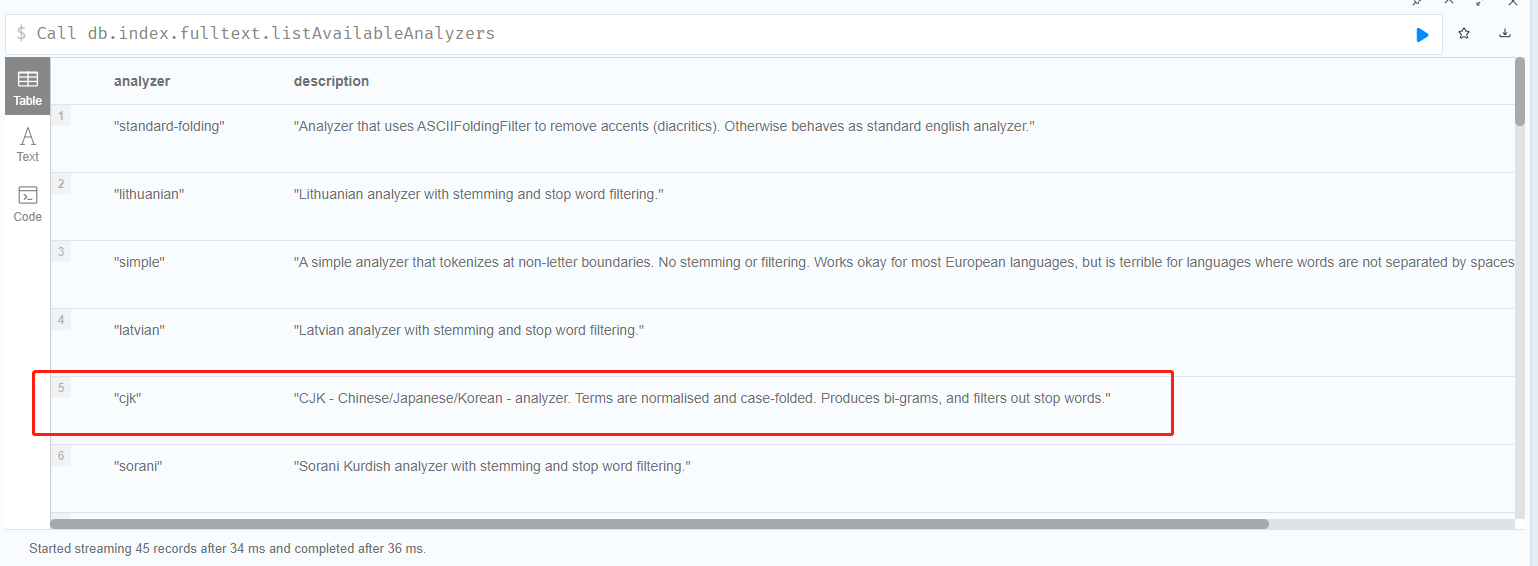
1. 使用neo4j自带中文分词器
通过db.index.fulltext.listAvailableAnalyzers可以查询到"cjk"
2. 通过java代码引入第三方分词器
首先指定IKAnalyzer作为第三方分词器,先是引入IK的maven包
创建索引的核心方法
@Override
public void createAddressNodeFullTextIndex () {
try (Transaction tx = graphDBService.beginTx()) {
IndexManager index = graphDBService.index();
Index<Node> addressNodeFullTextIndex =
index.forNodes( "addressNodeFullTextIndex", MapUtil.stringMap(IndexManager.PROVIDER, "lucene", "analyzer", IKAnalyzer.class.getName()));
ResourceIterator<Node> nodes = graphDBService.findNodes(DynamicLabel.label( "AddressNode"));
while (nodes.hasNext()) {
Node node = nodes.next();
//对text字段新建全文索引
Object text = node.getProperty( "text", null);
addressNodeFullTextIndex.add(node, "text", text);
}
tx.success();
}核心Api
index.forNodes("addressNodeFullTextIndex", FULL_INDEX_CONFIG, IKAnalyzer.class.getName()))
查询全文检索的核心方法
public class AddressNodeNeoDaoTest {
@Autowired
GraphDatabaseService graphDBService;
@Test
public void test_selectAddressNodeByFullTextIndex() {
try (Transaction tx = graphDBService.beginTx()) {
IndexManager index = graphDBService.index();
Index<Node> addressNodeFullTextIndex = index.forNodes("addressNodeFullTextIndex" ,
MapUtil. stringMap(IndexManager.PROVIDER, "lucene", "analyzer" , IKAnalyzer.class.getName()));
IndexHits<Node> foundNodes = addressNodeFullTextIndex.query("text" , "苏州 教育 公司" );
for (Node node : foundNodes) {
AddressNode entity = JsonUtil.ConvertMap2POJO(node.getAllProperties(), AddressNode. class, false, true);
System. out.println(entity.getAll地址实全称());
}
tx.success();
}
}核心Api
db.index().forNodes(indexName, FULL_INDEX_CONFIG).query(queryParam)
3. 第三方库实现中文检索
其实内部原理和方法二的逻辑是一样的。只是对其进行了更好的封装。支撑直接调用https://github.com/crazyyanchao/ongdb-lab-apoc

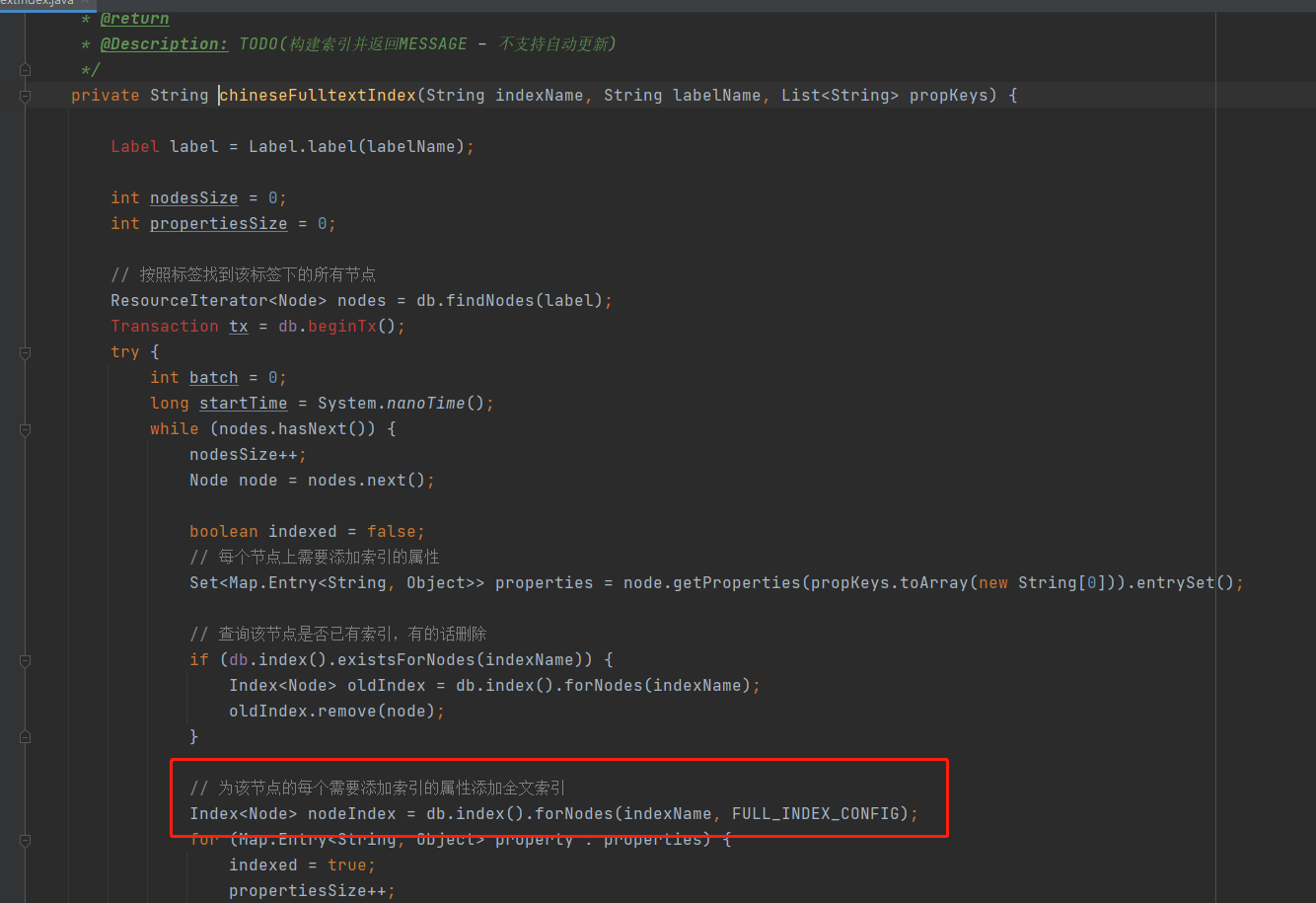
创建全文索引核心代码
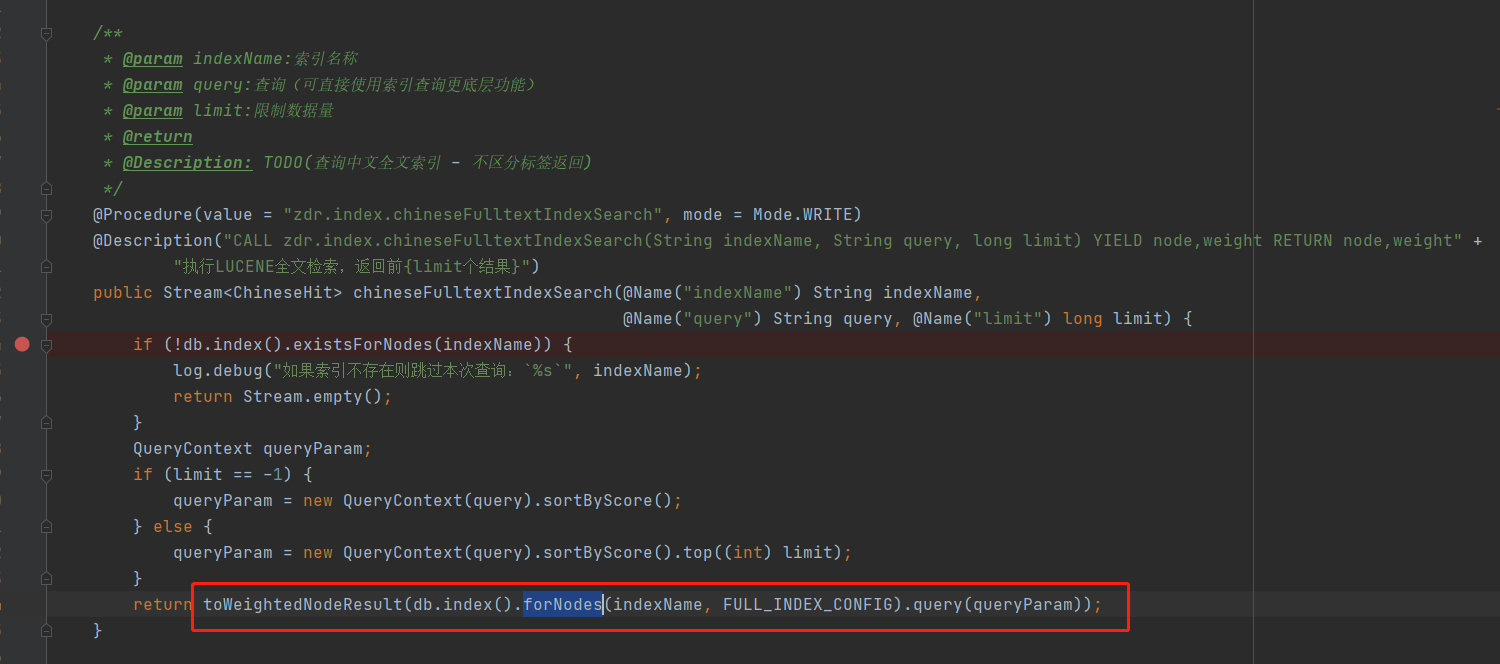
查询全文索引核心代码
引用第三方包的方式
加载neo4j-graph-plugin-1.0.1.jar放入neo4j中的plugins包下面
修改配置文件conf/neo4j.conf文件
dbms.security.procedures.unrestricted=apoc.*,zdr.*把源码中的dict文件放到neo4j根目录下面
可以在dic/dic-cfg/user-dic/user_defined.dic自定义自己的分词词典
参考文献



默认评论
Halo系统提供的评论